Handle Parsing Errors
When your pipeline has parsing errors, that means some records were not sent to the destination.
In most cases, parsing errors are caused by mismatching data types or data that a transform can’t handle. For instance:
- when you wrangled the data before creating the pipeline and the sample data only had integers, but newer data has decimals
- when a JSON parsing transform or URL parsing transform were applied to invalid JSON or URL data
- when you used a default script to skip wrangling but the data in the source could not be processed properly (see the previous reason)
- when the Flatten JSON Object transform tries to parse a non-object value for a field that is specified as a nested JSON object.
The pipeline will then either halt completely or skip the invalid rows as they would not be allowed in the destination column. Which scenario will take place depends on your pipeline settings.
How Do You Know About Parsing Errors?
You will see the notifications about parsing errors from several places in your account. You’ll also get notified by email if the pipeline was run for the first time.
Home page/Dashboard
All pipelines with parsing errors that exceed the defined threshold are displayed here. You can read more about defining the threshold in the Define Parsing Errors Settings section.
Pipeline Page: Overview
You can view the total number of parsing errors (1) for the time frame selected (2).
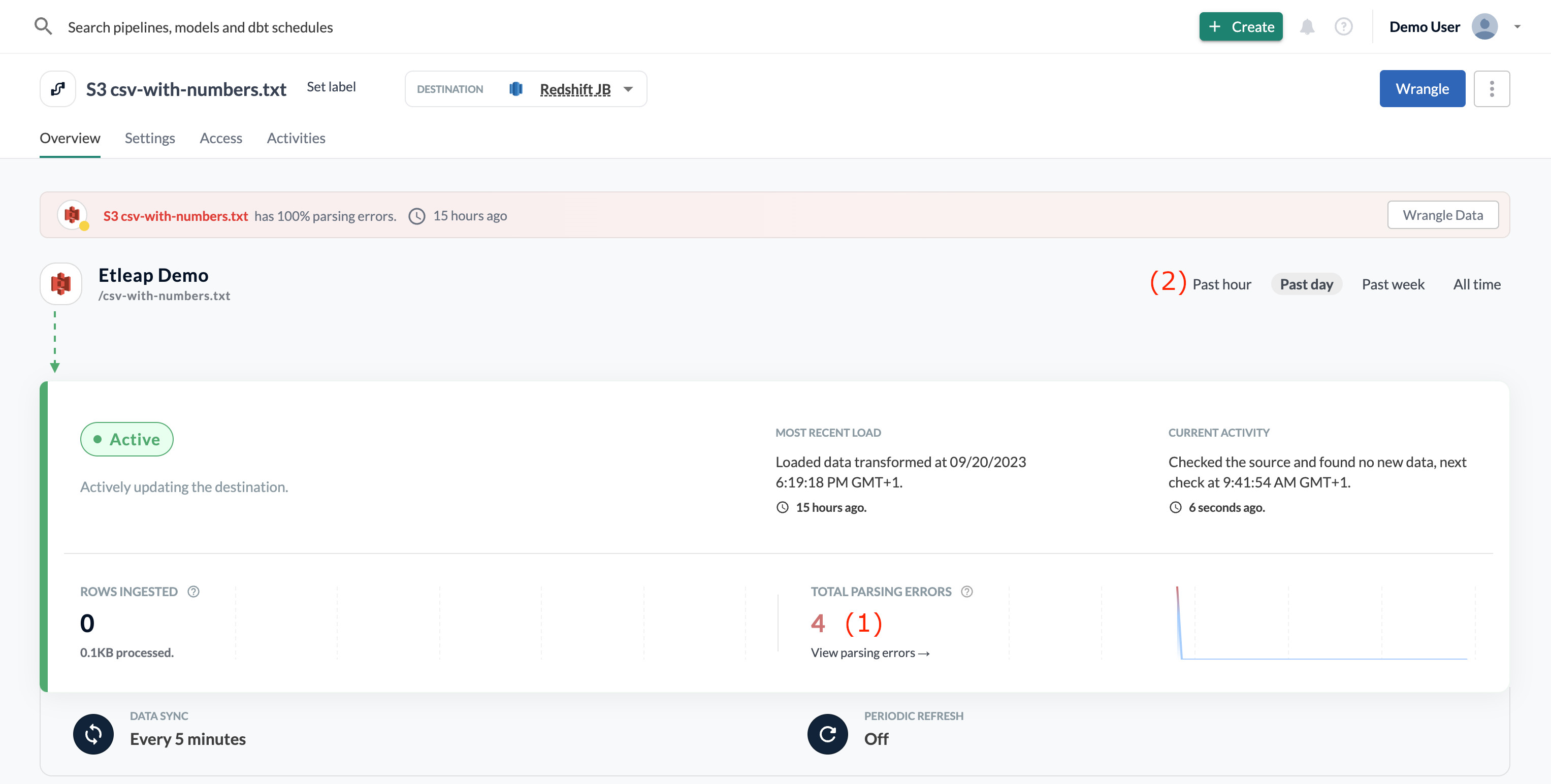
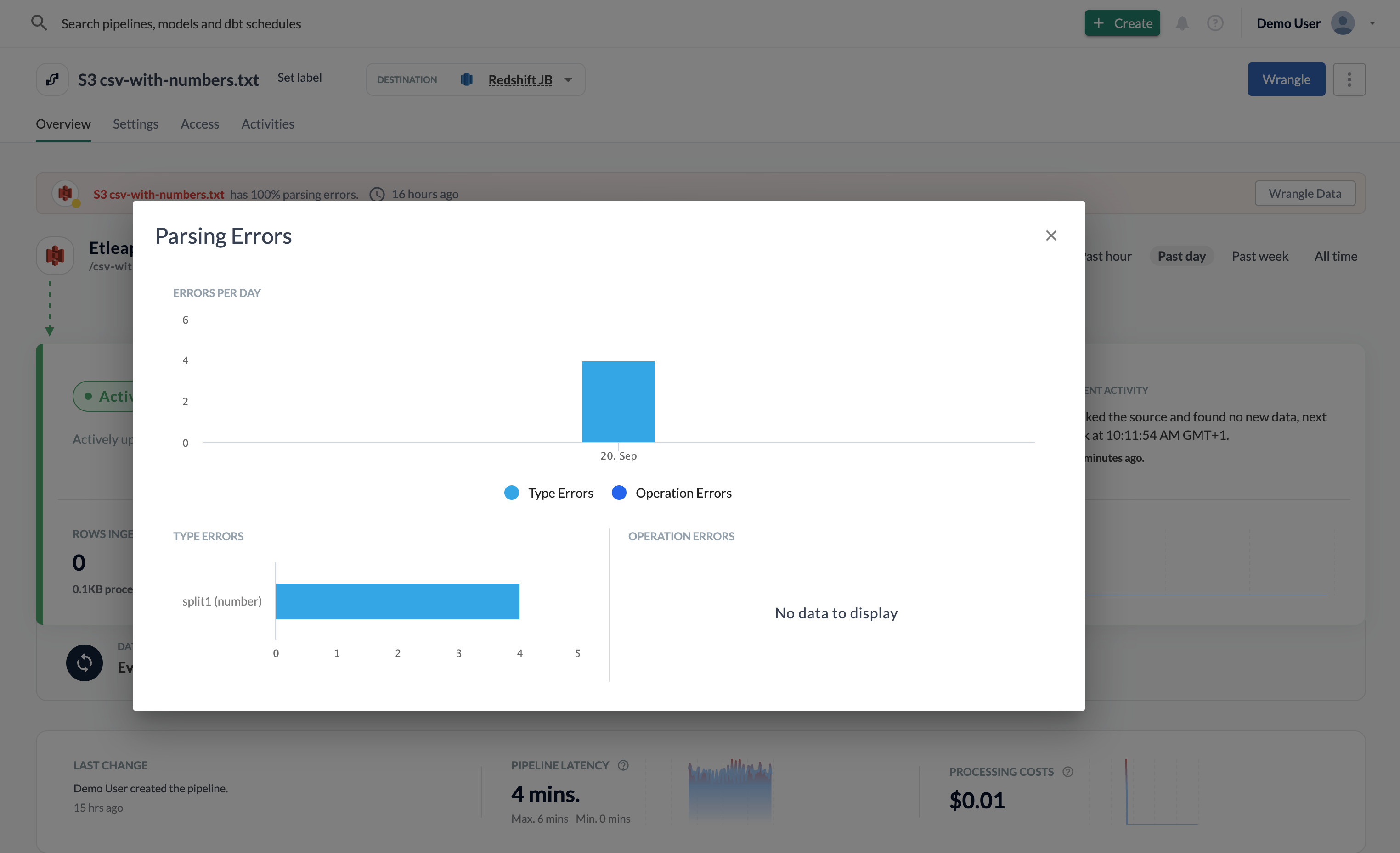
Click the link to View Parsing Erorrs if you want more details on the number of errors per day and the type of error. You can read more about the different parsing error types in the Types of Parsing Errors section.
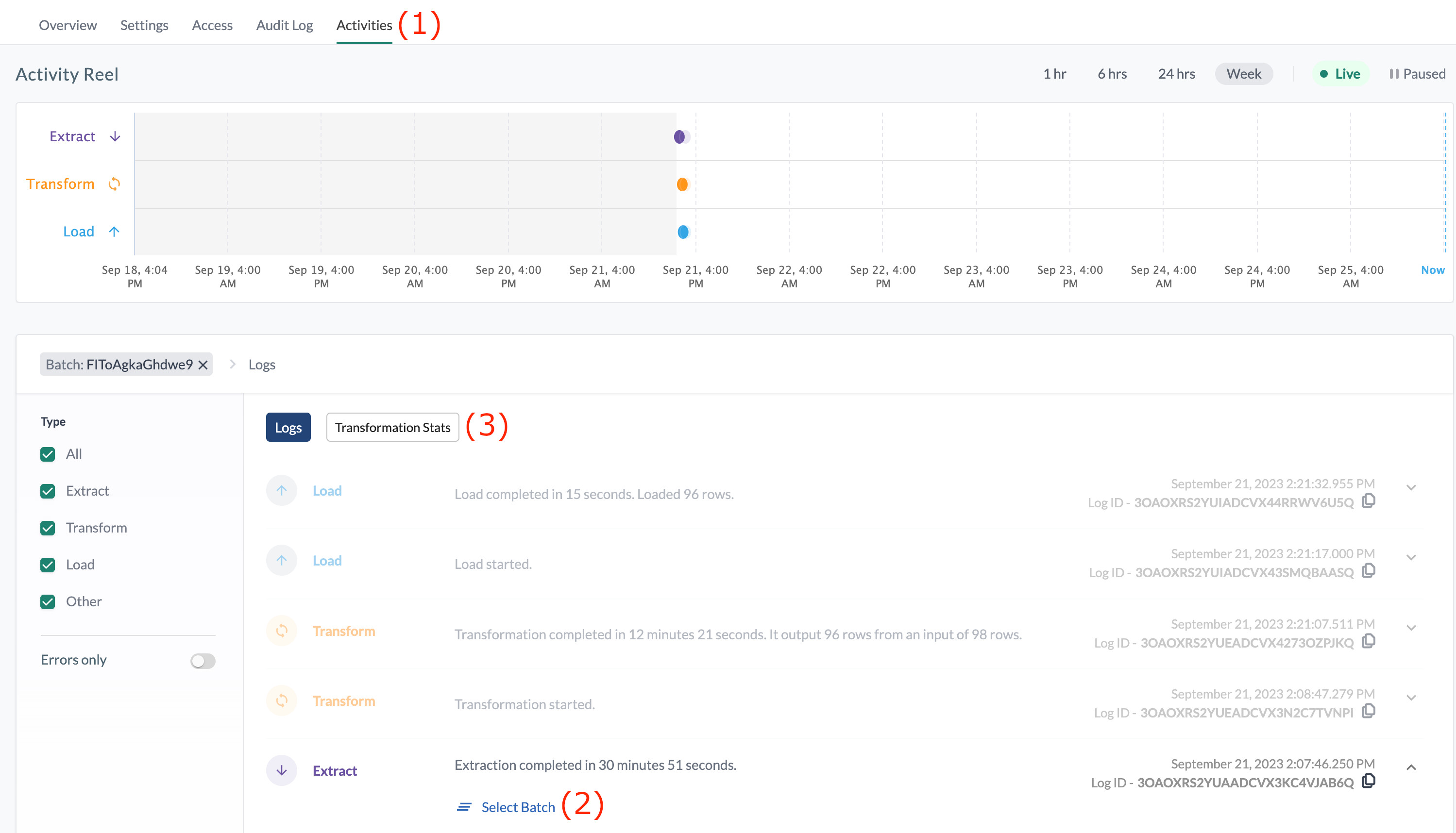
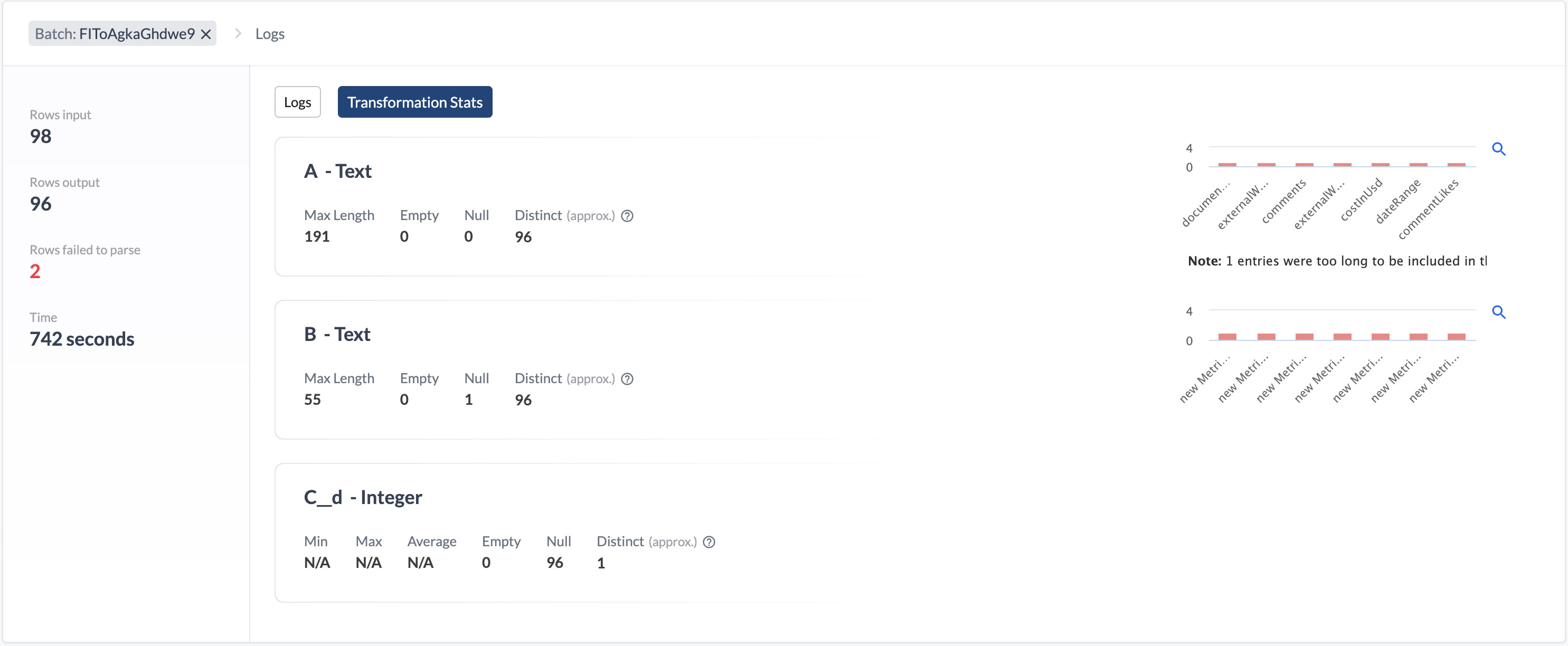
Transform Report
On the Activities tab (1), you can also drill down into a pipeline batch’s (2) transformation stats (3) of a given batch
The Transformation Stats shows parsing errors as the number of rows that were not parsed properly per transformation. It can also give you an idea about the reasons the parsing errors happen, for example, if you see the wrong data type in some columns.
Fixing Parsing Errors in the Wrangler
You can add steps in the Wrangle to eliminate parsing errors that are usually related to invalid data in the dataset. Read more about this in the invalid data section.
Updating the Wrangler Automatically
Go to the Pipeline with parsing errors’ Wrangler. The Wrangler should suggest that you deactivate the step that is failing to parse data.
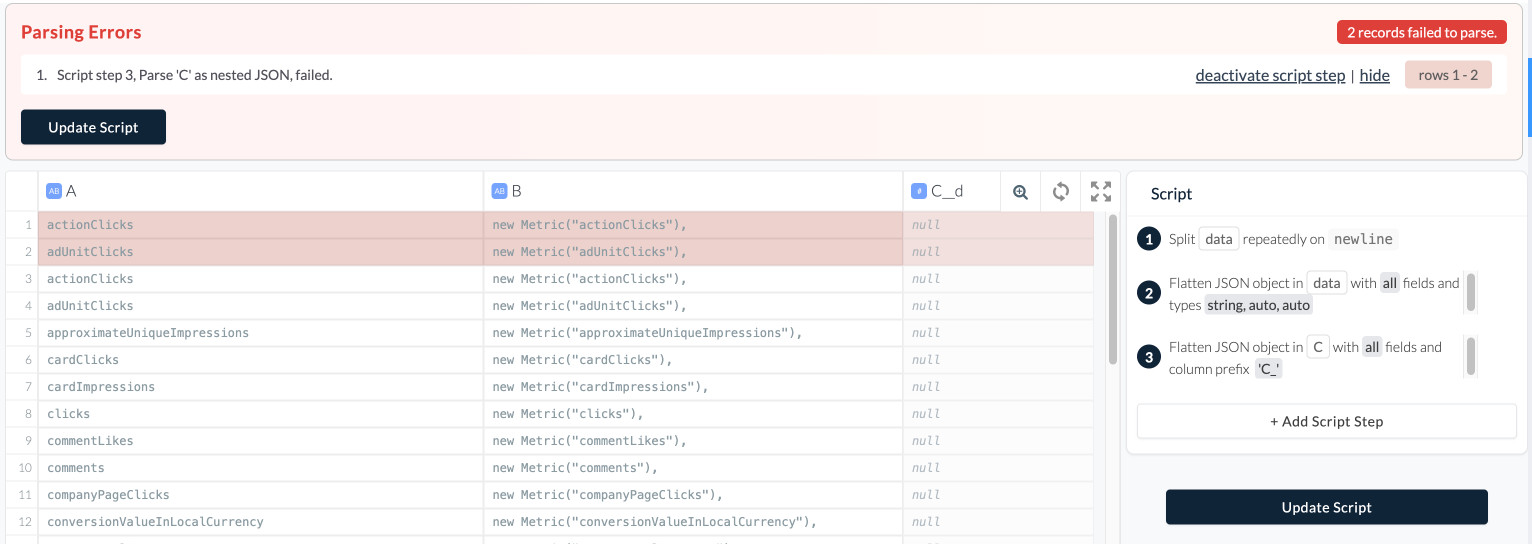
Once you do so, it will show the affected rows before the transformation, and you can decide how to deal with them. It may make sense to handle them directly in the Wrangler (see our invalid data tutorial or in the source. The latter is applicable e.g. to file-based sources where you can replace the troublemaking file with a corrected one.
In some cases, it will suggest you updating the Wrangler script by adding a step. The new step is already in the Wrangler. If you agree with the change, just click “Update Script”.
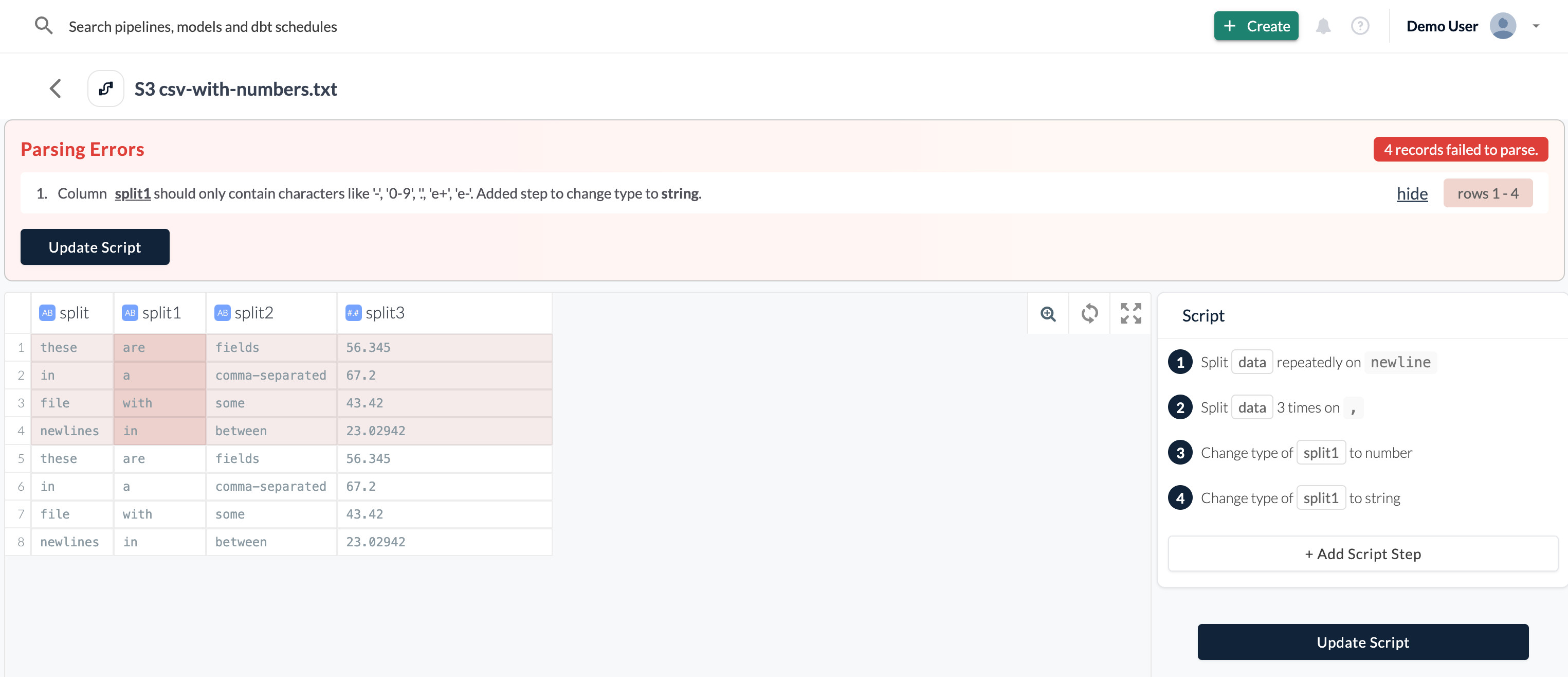
Adjusting the Wrangler Manually
In the example above, the Wrangler converted the whole column into string to fit the missing rows into the dataset. You can reject the suggested transformation step and add another one. For instance, if later in the destination you need to perform any calculations on this column, you’ll need to cast it back to integer first.
To reject the step, hover over a surface right to the last (newly added) step and click the stop sign icon and then the red cross.
Depending on what caused a parse error — typically, it would be a wrong data format — proceed with one of the methods described in the invalid data tutorial.
What Happens Next
Once you have updated the script, the pipeline will start a refresh. It will fetch all available data in the source and re-process it using the new script.
During the refresh, the already existing table in the destination will remain accessible. Once the refresh is completed, the data in it will be replaced with the new one.