Pipeline Options for a File Source
File Filtering
The file picker allows you to apply a filter to further limit which files Etleap ingests. File filtering can be used to identify files of a certain type or naming convention. Depending on your source type, Etleap offers two ways to filter files: Filename Regex and Glob Pattern.
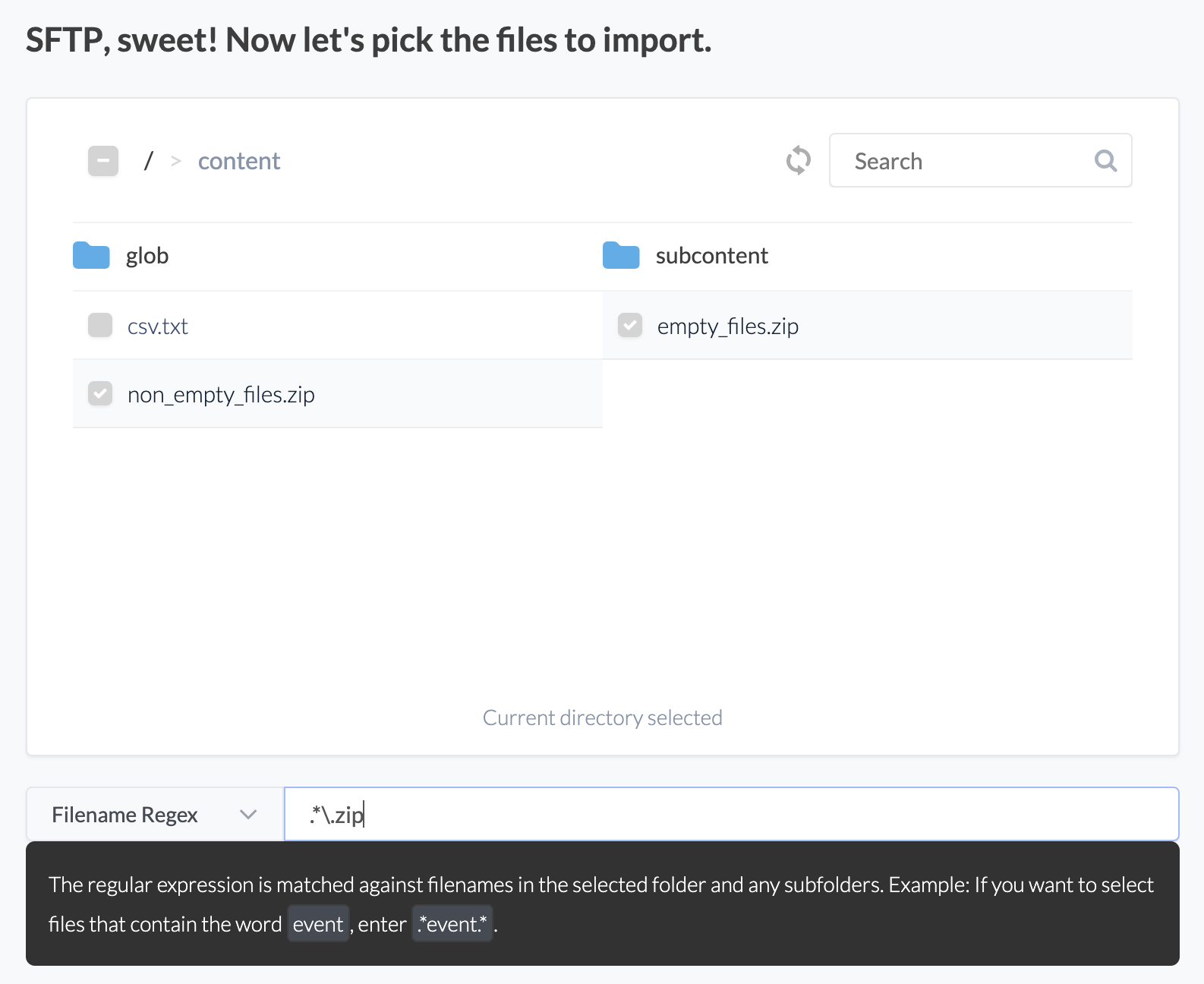
Filename Regex
Etleap enables you to define a filename regex pattern to selectively filter files that correspond with this specified pattern. Upon setting a regex pattern, Etleap initiates a full search for files within the chosen directory and its subdirectories, and then extract only the files that match the regex pattern.
Filename regex is available for all file sources.
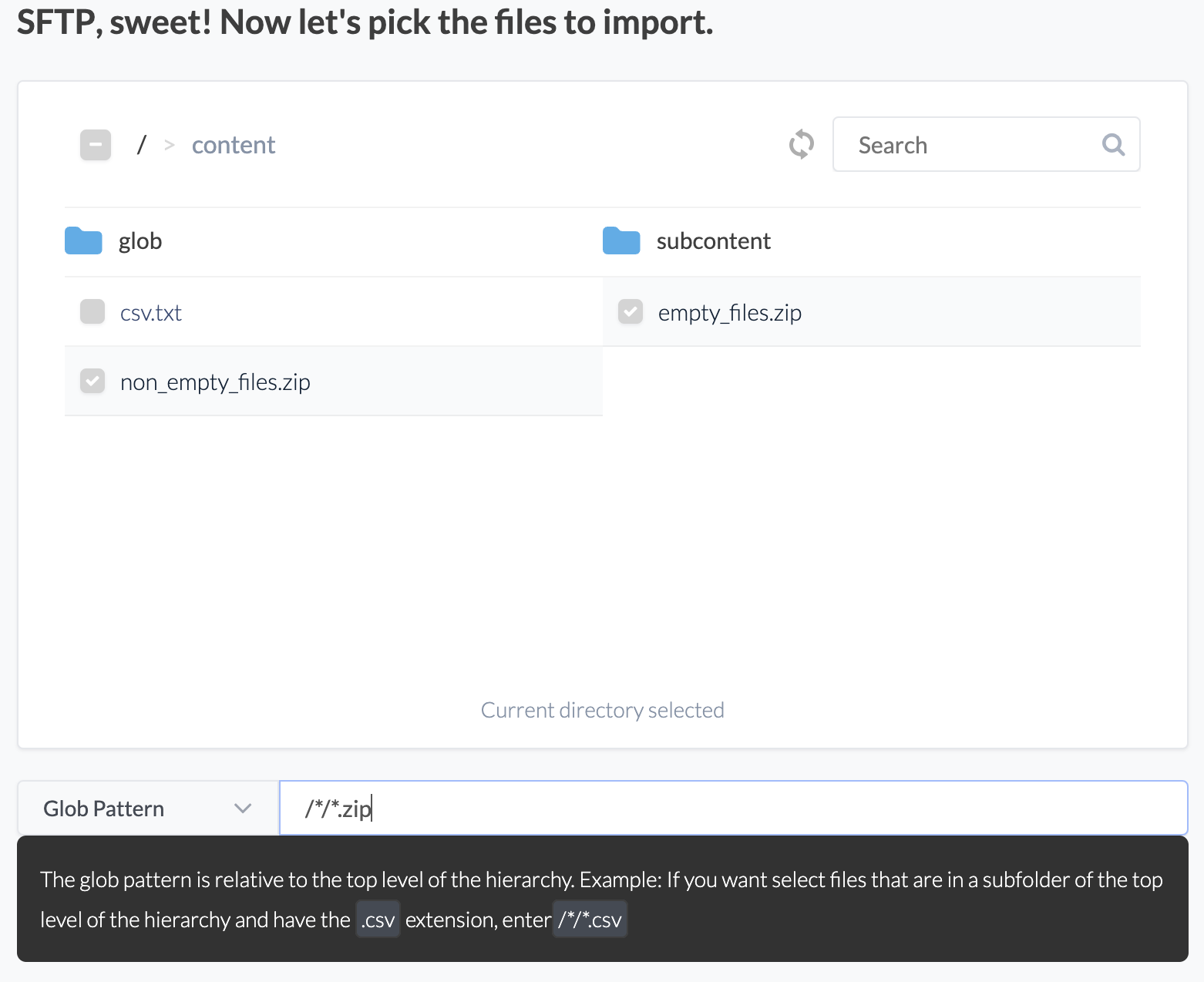
Glob Pattern
For certain source types, utilizing a glob pattern is an option. When this approach is employed, Etleap executes a search from the root directory, focusing exclusively on files situated at the level delineated by the glob pattern. Files are only returned if they fulfill the criteria set by the glob pattern.
Glob pattern filtering is available for all file sources with the exception of S3.
Pipeline Options
After wrangling and choosing the destination, pipeline name, path or glob pattern you are given some additional source options.
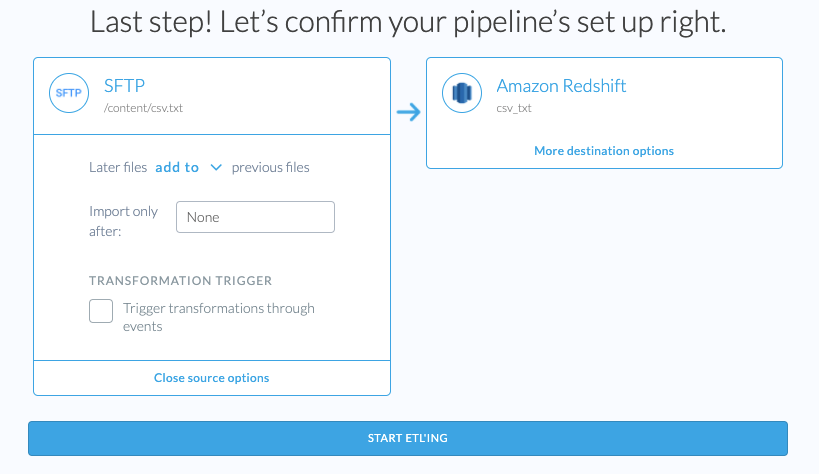
None of these sources options can be changed after the pipeline is created. If you wish to change these later, you will need to recreate the pipeline.
Update Method
In all pipeline modes the files are processed in order of their modification timestamp.
- Later files
add toprevious files: new files that the pipeline discovers will be appended to the existing data. For S3 sources this will also enable Files Change options. For more details see: Append Mode. - Later files
replaceprevious files: Each file is assumed to contain the full contents of the source, therefore the pipeline will only process the file with latest modification timestamp in that folder. For data warehouse destinations it will perform a full rebuild of the table, removing all existing data and adding the data from the new file. For more details see: Replace Mode. - Later files
updateprevious files: the destination settings will require you to specify the Primary Key column(s) for this data. When new data is processed, rows with a primary key that already exists in the destination will be updated, while records with a new primary key are inserted into the destination. The data will be deduplicated using the Primary Key and Last Updated Mapping, where the row with the latest value in the Last Update Mapping column is selected for a Primary Key. In the case that the last-updated column values are equal, the record that appears last in the file will be selected. This ensures that only one row exists for every Primary Key in the destination. For more details see: Update Mode.
Import Only After
The pipeline will only process files that were modified after the date specified. This is helpful if you have tens of terabytes of data in the source and do not need to process all of the historical data.
Transformation Trigger
When the Trigger transformation through events option is enabled in the source setting during the pipeline creation time, instead of relying on update schedule, the pipeline will process new files when it receives a Batch Added Event .
To enable this feature please contact support.