Partition Output by Values
Partitions data in your data lake using column values. You can find more information on data partitioning here.
Example
| id | path | event_type | region |
|---|---|---|---|
| 0 | /logout | click | east1 |
| 1 | /home | pageload | east1 |
| 2 | /user | pageload | east1 |
| 3 | /home | pageload | west1 |
| 4 | /logout | logout | west2 |
| 5 | /settings | click | east1 |
| id | path | PARTITIONS |
|---|---|---|
| 0 | /logout | click, east1 |
| 5 | /settings |
| id | path | PARTITIONS |
|---|---|---|
| 1 | /home | pageload, east1 |
| 2 | /user |
| id | path | PARTITIONS |
|---|---|---|
| 3 | /home | pageload, west1 |
| id | path | PARTITIONS |
|---|---|---|
| 4 | /logout | logout, west2 |
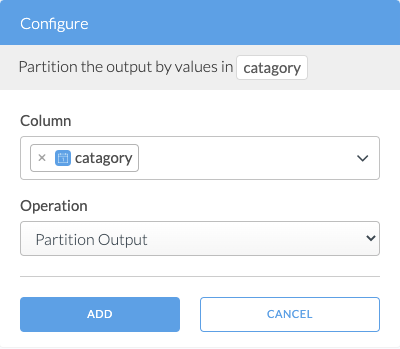
Configuration
Column
Select the columns that the transformation output data will be partitioned by.
Any columns selected in this step will be removed from the output data and encoded in the path of the output files.
Operation
Leave the Operation value as Parition Output for this transformation.
Effect on Output Data
When this step is added to a transformation script, the output of that transformation will be partitioned by the selected columns. When more than one column is selected as partition keys, the order in which the columns are specified in the transform determines the order in which the data is partitioned.
For example, if the event_type and region columns are selected as partition keys, the files loaded to the Data Lake destination will be organized by the following directories:
s3://bucket-name/output_path/v{version}/{event_type}/{region}/{load_date}/{is_deleted}There will be one directory for each distinct combination of values across the selected partition columns. If the Data Lake connection is configured with a Glue database, then the tables created in Glue will contain a partition for each combination of column values in the selected columns.
See Data Partitioning for more information.
Key Considerations
- This transform can only be added to a Wrangler script once.
- This transform is only valid for S3 Data Lake destinations.