Data Partitioning
In data lakes it’s often useful to partition incoming data based on attributes in the data itself. Here’s how to do that in Etleap:
- In the wrangler, click ‘Add Step’, and pick ‘Misc’.
- In the ‘Operation’ dropdown pick ‘Partition Output’.
- In the ‘Column’ input, enter the column(s) you want to partition by. Multiple columns can be specified as a comma-separated list.
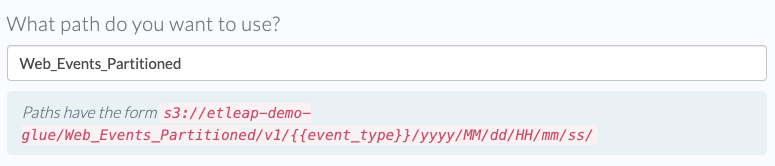
- Click ‘Add’ and ‘Next’.
- Pick your S3 Data Lake destination.
- On the following page, you will see that in the S3 path template there’s a placeholder for the partition column in the S3 path, which will be replaced by the partition value. Note that this placeholder comes just after the pipeline version indicator and before the load time partitioning.
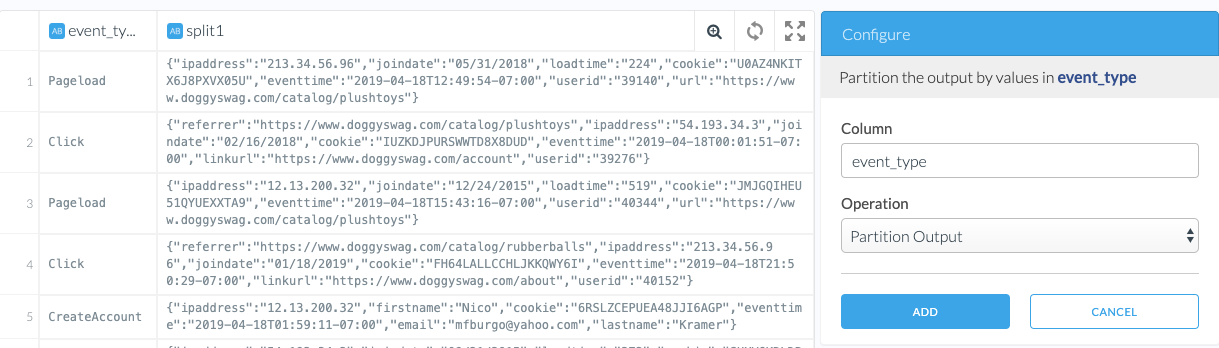
By default, Etleap adds up to 2 extra partitions:
-
_loaddatewhich is the date when data was loaded, in ISO8061 basic format -
_id_deleted, which is enabled only for Parquet Output, and istruewhen the primary keys are deleted from source, when we support extracting deletes (e.g. Salesforce or Database CDC).