Create a File Based Pipeline
This article explains how to create a pipeline using S3 Input, FTP, SFTP, or Google Cloud Storage (GCS) as a source. The pipeline will pull from one or many files and transform them according to a single script.
Prerequisites:
- You have set up or someone in your Etleap organization has shared a file-based source connection: S3 Input, FTP, SFTP, or Google Cloud Storage (GCS).
- You have at least a basic familiarity with how to Wrangle data.
- You have one or more files that you want to transform with the same script.
- All files have the same file schema.
Step 1: Pick the Source
- Click the +Create button in the top navigation panel.
- Select the source connection.
Step 2: Select the Input Files
The file picker shows a directory listing at the input path specified for the connection. Navigate to a subdirectory by clicking on it. Navigate back to the parent directory by clicking on the slash ”/” at the top left.
You have a few options for how to specify the input files:
-
Specific files. Select the files by clicking their checkboxes. Only those files will be processed by the pipeline.
-
Entire directory tree. Navigate to the desired directory and click the checkbox next to the ”/” at the top left. All current and new files in that directory (including subdirectories) will be processed by this pipeline.
-
Files matching a filename pattern. Specify a filename filter. All current and new files in the current directory or subdirectories that match the regular expression will be included. When you enter the pattern, the file picker will add a checkmark to the files that match the pattern. If you’re unfamiliar with regular expressions, see this quick introduction . The example below matches all json.gz files that start with “event-0000” and end with 2, 3, 4 or 5.
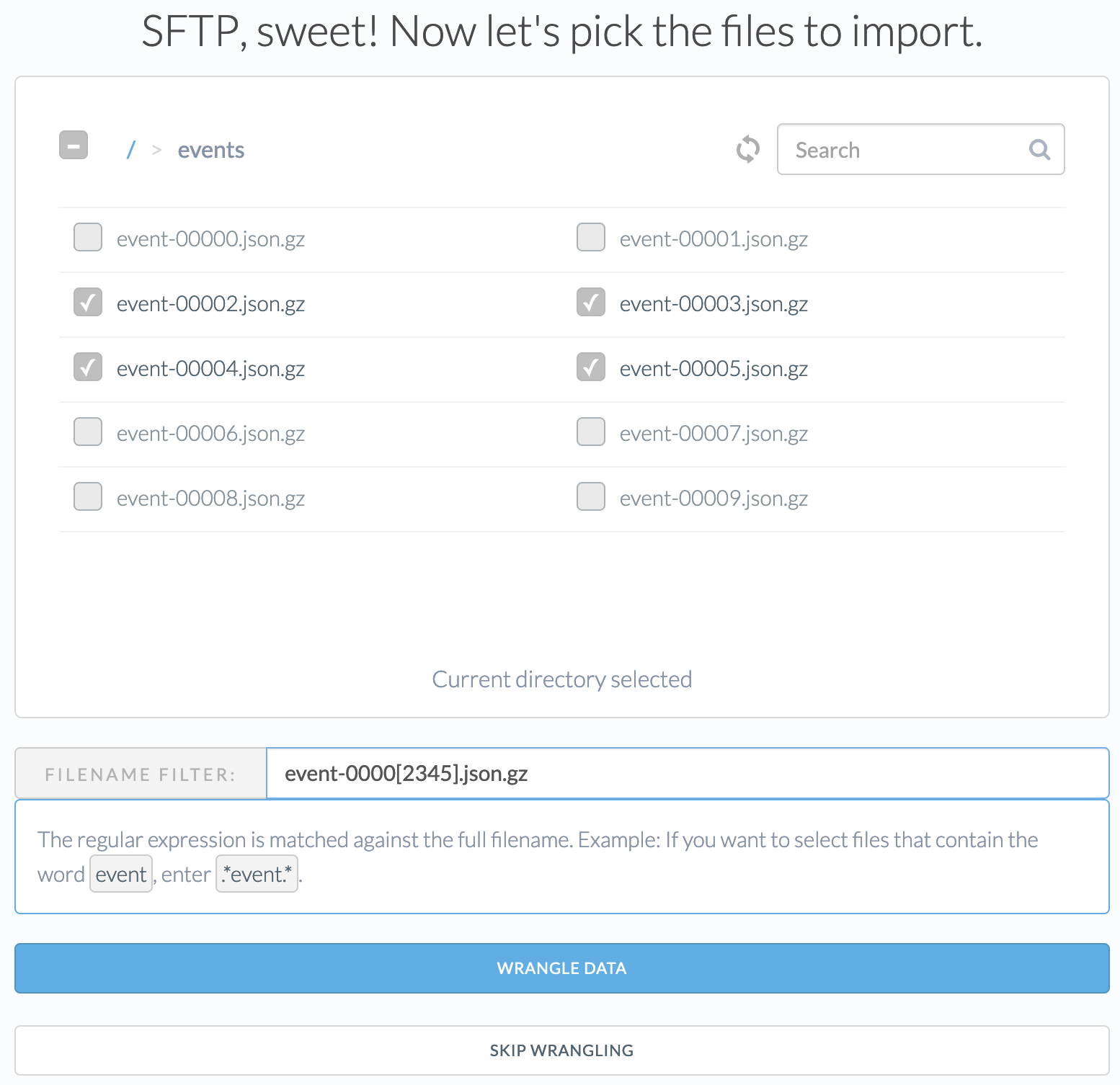
Once you have selected the files, click Wrangle Data.
Step 3: Wrangle the Data
This section will describe some things to keep in mind when wrangling for file-based sources. Because files tend to have less structure than other source types, you will likely need to do more wrangling than normal to get it into the desired structure. If you are new to wrangling, consider reading the documents listed under User Guides > Wrangling Data before continuing.
Step 3.1: Confirm the Input Format
The first transform step in the script is the Wrangler’s best guess at the correct way of parsing the file. Confirm that the data sample looks as expected. If it doesn’t, see the sections below.
JSON Data
If your data contains JSON - looks something like {"key1":"value1", "key2":"value2}, then see this overview of JSON Parsing
XML, Parquet, or Avro Files
These formats are automatically detected by the Wrangler. There are many edge cases with these formats, so contact support if the Wrangler isn’t properly parsing your files.
CSV or Other Plain-Text Formats
If the file extension contains .csv, .tsv, .txt or does not have a file extension, then you will need to ensure that the Wrangler uses the right transform for parsing. Select Parse CSV and choose the appropriate escape and quote character.
Troubleshooting
If the parsing looks incorrect (wrong number of columns or multiple rows bunched into one, or the data just looks like nonsense), then contact Etleap Support for assistance in choosing the correct parsing steps.
Step 3.2: Set the Column Names If Needed
Some file formats like plain-text don’t have metadata to specify the columns names. If the column names aren’t correct, you can specify them in one of the following ways:
- If every file has a header row, click the row number 1 on the far left and select the suggestion on the right for Promote to Header.

- If none of your files have a header row, then you can set the column names manually using the Rename All transform.
- If your files have inconsistent header rows (the columns are named differently or columns are added or dropped between files), then contact Etleap Support for how to handle it.
Step 3.3: Parse Individual Columns as Needed
Some columns may need additional parsing steps for the Wrangler to recognize its type, clean the data, or structure the text to be more queryable. Common use cases include:
- Hnadling dates, date-times, and integer timestamps
- Parsing JSON objects or arrays
- Removing invalid data
- Extracting or manipulating text
Step 3.4: (Optional) Add Metadata Columns
Consider adding metadata columns, in order to help with analysis and diagnosing any issues later.
Step 4: Choose the Source Options
After wrangling and choosing the destination, pipeline name and path, you are given some additional source options.
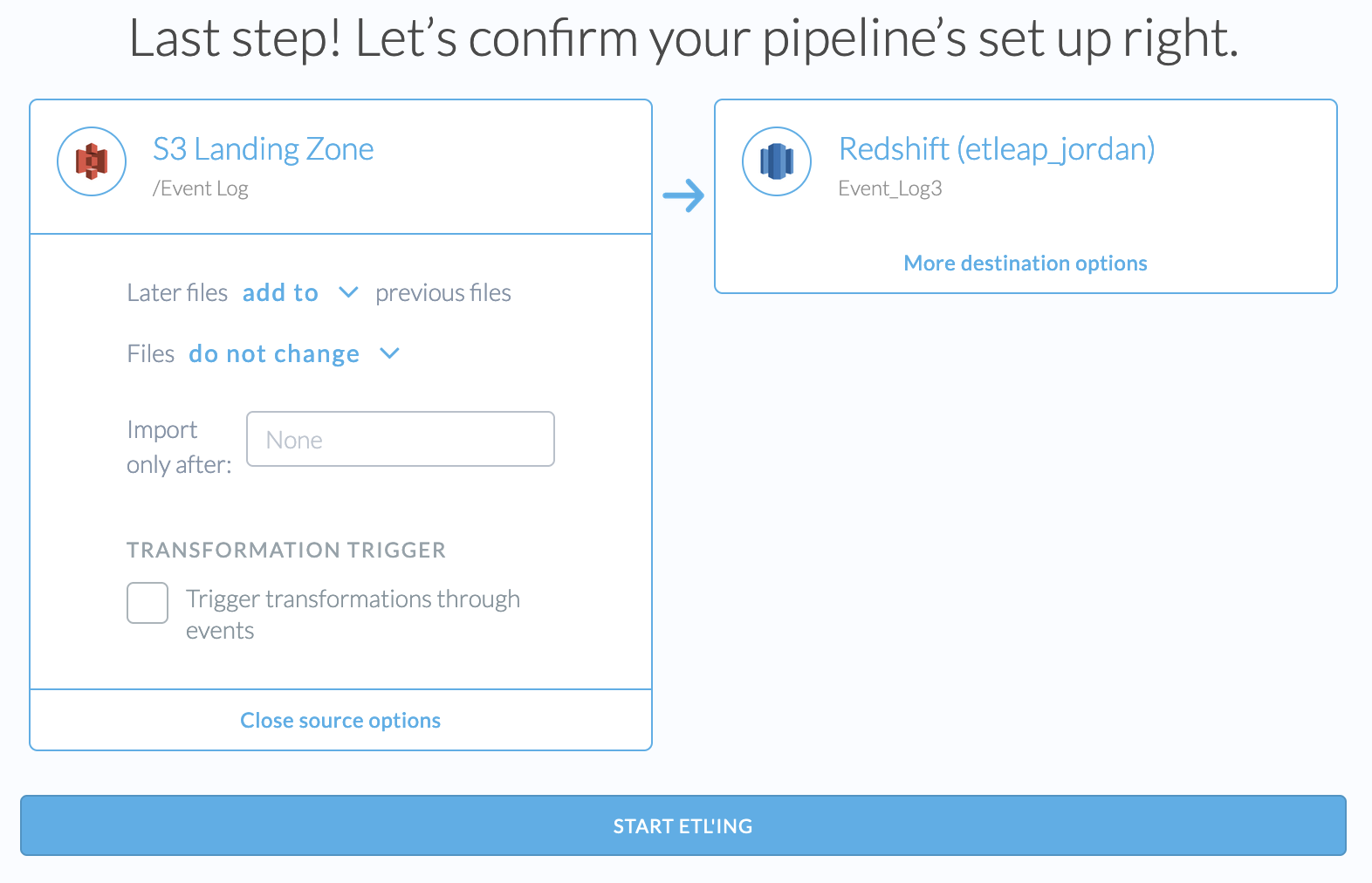
None of these sources options can be changed after the pipeline is created. If you wish to change these later, you will need to recreate the pipeline.
Update Method
- Later files add to previous files: new files that the pipeline discovers will add to the existing data.
- Later files replace previous files: when the pipeline discovers new files, it will transactionally remove existing data in the destination and then add the data from the new file.
- Later files update previous files: the destination settings will require you to specify the Primary Key column(s) for this data. When new data is processed, the pipeline will transactionally remove old data in the destination that matches the primary key found in the new data before adding the new data.
Files Change
When using an S3 Input source and if later files add to previous files, you have the option of specifying whether we assume that files change.
- Files do not change means that we will not check whether a file has changed in the source and only process new files. This improves pipeline performance compared to the option below.
- Files sometimes change means that Etleap will check whether files that were already processed have changed. If the file has changed, then Etleap fetches the new file and removes the old file’s data in the destination and adds the changed data. This option adds a new column
file_path_hashto the destination table which it uses for detecting records that came from an old file.
Import Only After
The pipeline will only process files that were modified after the date specified. This is helpful if you have tens of terabytes of data in the source and do not need to process all of the historical data.
Transformation Trigger
Instead of the pipeline running when it discovers new files, the pipeline will only process new files when it receives a Batch Added Event . Contact support for enabling this feature.
Step 5: Choose the Destination Settings
After choosing the destination settings, click Start ETL’ing and you’re good to go!