Flatten JSON Object
Parses a JSON tree and create a new column for each leaf property, using the key path as the column name and value as the cell content.
Example
| data |
|---|
| {"a": "value_1", "b": { "b1": "value_2", "b2": "value_3" }} |
| {"a": "value_4", "b": { "b1": "value_5", "b2": "value_6" }} |
| data_a | data_b_b1 | data_b_b2 |
|---|---|---|
| value_1 | value_2 | value_3 |
| value_4 | value_5 | value_6 |
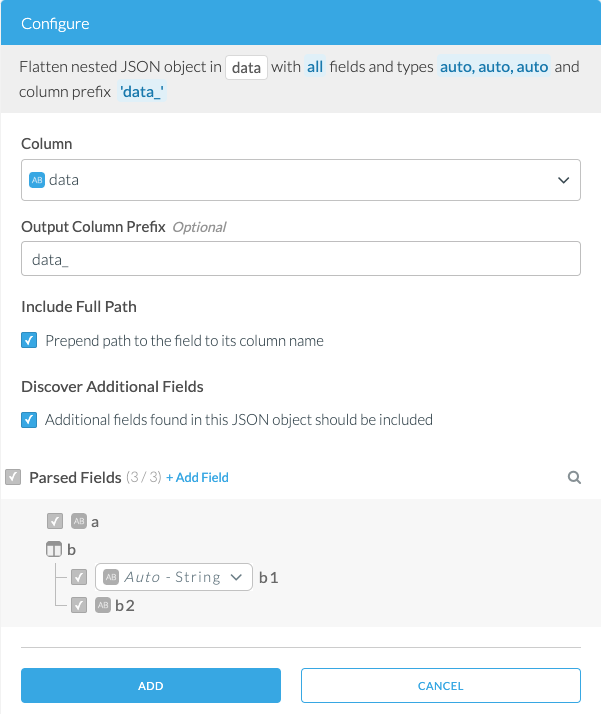
Configuration
Column
Select a column to parse as nested JSON.
Output Column Prefix (Optional)
Specify a prefix for the column names.
Include Full Path
Specify whether the column name should include the full path to the node in the nested JSON object.
Discover Additional Fields
When enabled, any new fields that are discovered while processing the data will be automatically included in the transform. More information.
Parsed Fields
Specify the structure of the nested JSON object. You can specify the following:
- Types: Click the type icon next to a field name and select a type in the drop-down.
- Add custom fields: You can add new fields on the top-level of the JSON and on nested objects. Hover over the Parsed Fields header or the name of any object in the tree, and click on + Add Field.
- Exclude fields: Uncheck the checkbox next to a field to exclude it. Unchecking requires Discover Additional Fields to be disabled.
- Specify nested object as string: You can override the type of a nested object to be a string. The output column will contain the nested JSON object as a JSON string. Click the type icon next to a nested object name to change the type to
String.
You can search for fields in the nested JSON object and highlight fields in the table view of the Wrangler to simplify navigating a nested JSON object structure. Use the magnifying glass icon next to the Parsed Fields header to search for fields. Click the magnifying glass icon next to a field name to highlight it in the table view.
Adding the Transform
- Select a column that contains JSON object data by clicking its column header in the table.
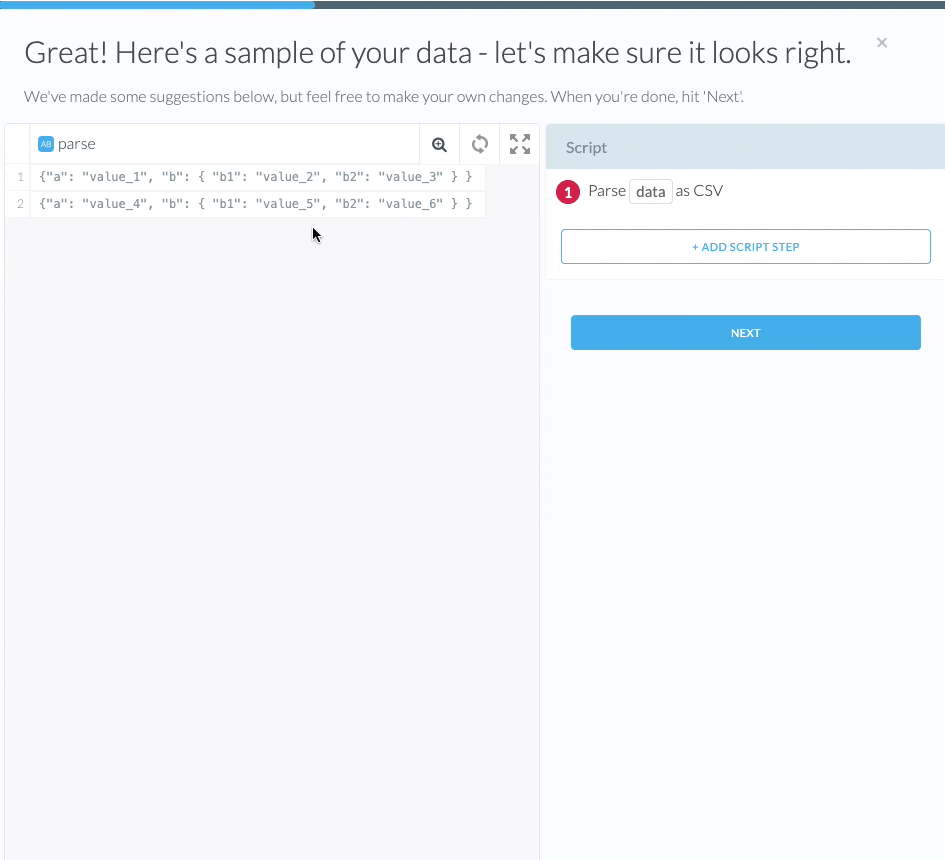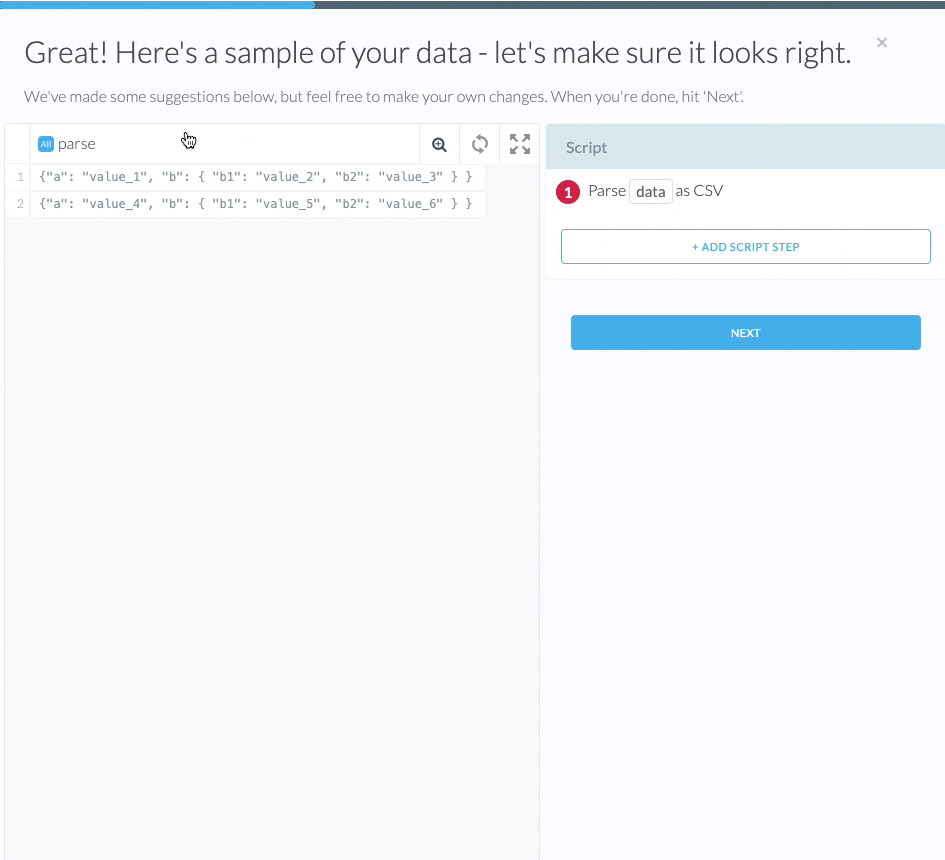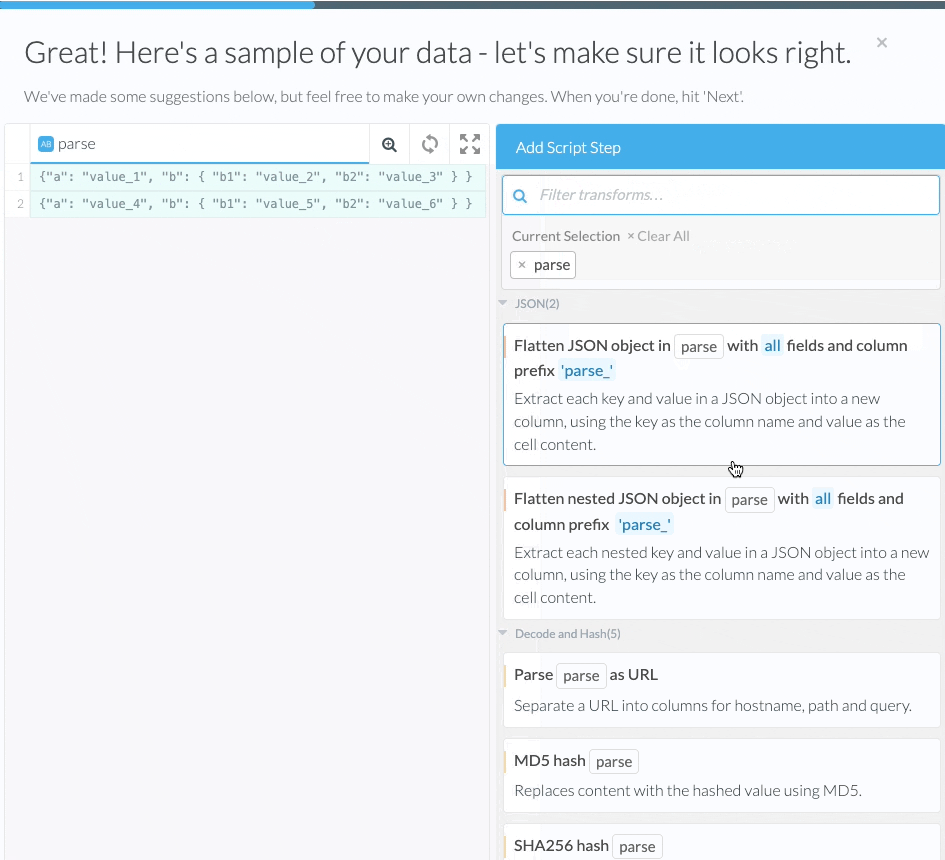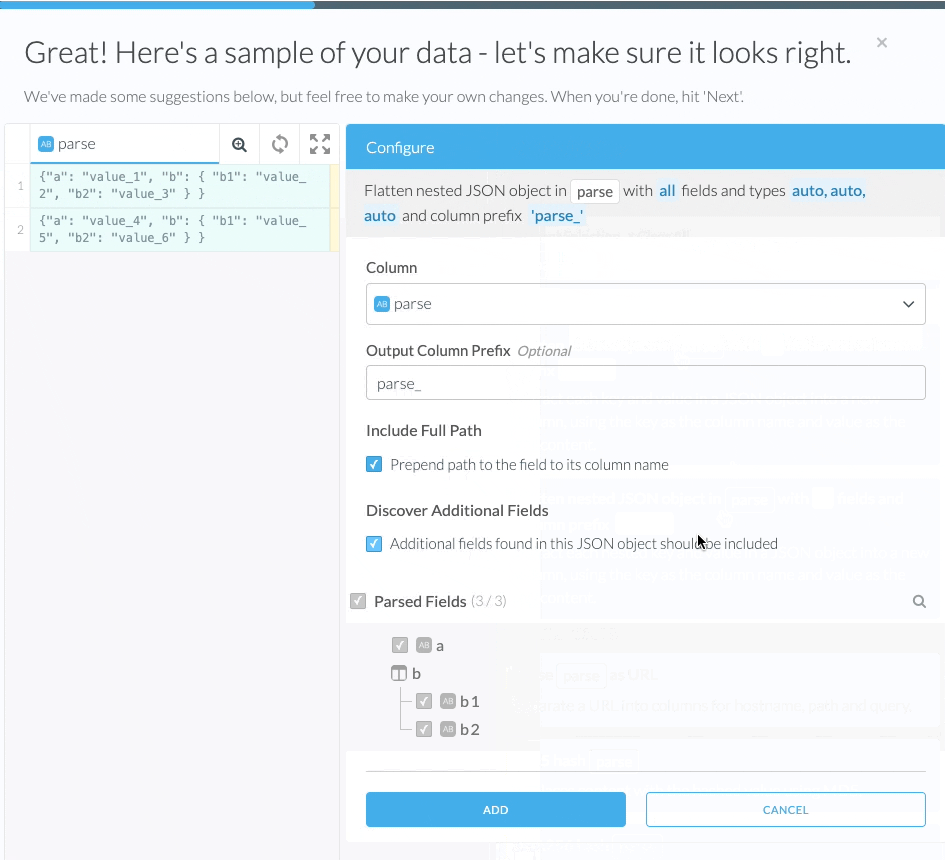
- Find the Flatten nested JSON Object transform under the JSON group.
Alternatively, you can click on + Add Script Step on the right of the wrangler to find Flatten nested JSON Object under the JSON group.
Discover Additional Fields
The Discover Additional Fields feature automatically adds new key/value pairs from your nested JSON object. This feature is useful when you don’t find the fields in the wrangling sample or when new keys are added to the JSON object while the pipeline is operational. Etleap discovers new keys within the nested JSON object recursively and notifies you of the update.
If your pipeline has automatic schema changes turned on, Etleap will automatically adapt the script to include the new JSON keys and the destination schema to include the new columns.
If your pipeline has manual schema changes enabled, Etleap stops the pipeline when discovering new JSON keys and notifies you of the change. You can view a sample containing the new keys in the Wrangler and review the adapted script for approval or edit. If you want to drop a discovered property, follow the steps outline here.
New properties will be parsed recursively whenever possible. If a single transformation sees a new property that is an object in some rows and a non-object (e.g. string) in other rows, the new field will be treated as an object and parsed recursively. This will result in a parsing error for the rows that have the property as a non-object. If you want to always discover new properties as strings, configure the pipeline for manual schema changes and specify the type of the new property as a string in the Wrangler when the new field is detected.
When a field is already configured in the transform as a type other than Object, any children of that field that appear in the data will not be discovered as new columns.
Instead, the column will contain a string representation of the JSON object for those rows.
If you want to parse the children into separate columns, the script in the Wrangler must be updated to set the field type to Object.
This will require a pipeline refresh.
Key Considerations
- This transform replaces the original columns with new columns.
- New columns will always be parsed recursively.
- The
Wide Integertype is deprecated, and scripts that’s use this type are not supported by API v2 endpoints. We recommend usingDECIMAL(20,0)instead.